Por Juan Pablo Carranza
Los procesos de actualización masiva del valor del suelo urbano pueden llegar a ser de magnitud considerable y requerir la generación de grandes volúmenes de datos y la intervención de profesionales especializados. Sin embargo, es mucho lo que puede hacerse con información libre y gratuita disponible en la web, para lograr resultados útiles en ciudades donde hay poca o deficiente información sobre el catastro económico, el mercado inmobiliario local o la performance del impuesto predial.
En la presente nota se aplican algunos de los conocimientos y lecciones aprendidas durante el revalúo masivo de la tierra en la Provincia de Córdoba, realizado en 2019, que además de innovar en aspectos metodológicos, aplicando técnicas de inteligencia artificial en la estimación del valor del suelo urbano y rural, priorizó la utilización de datos libres y software de código abierto. Un excelente resumen de la experiencia mencionada puede consultarse en los siguientes links:
Determinación de valores del suelo urbano – Córdoba, Argentina
Determinación de valores del suelo rural – Córdoba, Argentina
El objetivo de la presente exploración es analizar la calidad de los resultados de una estimación del valor del suelo que sólo utilice datos libres disponibles en el Mapa de Valores del Suelo de América Latina en conjunto con otras fuentes gratuitas de información, como datos de Open Street Maps o imágenes satelitales Sentinel 2. Todos los análisis desarrollados en este escrito fueron realizados en el software libre y de código abierto R, utilizando el IDE de descarga gratuita R-Studio.
En el proceso de estimación del valor del suelo se escogió aleatoriamente a la ciudad de Cochabamba (Bolivia) donde se registran 108 datos. Éstos fueron introducidos al proceso de estimación sin ningún tipo de control previo. Esta aclaración es importante ya que frecuentemente se suelen filtrar las observaciones, por ejemplo, mediante la aplicación de algún índice de auto-correlación espacial para identificar valores atípicos en el entorno. Sin embargo, nos interesa puntualmente evaluar la calidad de la información tal cual están incorporados al Mapa y su potencial en la predicción del valor del suelo.

Fuente: elaboración propia en base a datos abiertos de Valores del Suelo en América Latina
Sobre los datos abiertos extraídos de Open Street Maps fueron calculadas, para cada dato muestral, las siguientes variables independientes:
- dist_bancos, distancia al banco comercial más próximo.
- dist_vias_prin, distancia a la vía principal más próxima.
- dist_iglesias, distancia a la iglesia más próxima.
- dist_vias_sec, distancia a la vía secundaria más próxima.
- dist_escuela, distancia a la escuela más próxima.
Con la imagen satelital Sentinel 2 se realizó un proceso de clasificación, entrenando el algoritmo “Random Forest” para discernir en el mapa las áreas construidas de las no construidas. El proceso de entrenamiento para la clasificación de la imagen satelital es un modelo predictivo en sí mismo y no hace al tema principal de este escrito. La metodología aplicada se puede replicar paso a paso, siguiendo las pautas detalladas en la IDE de la Provincia de Córdoba, en el siguiente link. Una vez identificadas las zonas construidas, se realizó, para cada punto muestral, un análisis de entorno para construir la variable perc_edif, que informa la cantidad de píxeles construidos sobre la cantidad total de píxeles dentro de un radio de 500 metros lineales. Se sumaron además, las variables dist_max y dist_min, que informan sobre las distancias entre cada observación en la muestra y el dato de mayor y menor valor, respectivamente. Por último, se incorporaron las coordenadas al análisis para intentar dar cuenta de la dependencia espacial residual en la muestra e identificar algún tipo de tendencia geográfica.
Todos los cálculos realizados para estas 10 variables independientes fueron replicados sobre una grilla cuadrangular de puntos separados cada 100 metros lineales, sobre la cual se realizó la estimación del valor del suelo. Una vez conformadas las bases de datos de muestra y de predicción, se procedió al entrenamiento de tres algoritmos diferentes para evaluar la calidad de sus estimaciones: Random Forest, Support Vector Machine y Kernel K-nearest Neighbor. Para ello, se aplicó un proceso de validación cruzada en 10 grupos. El proceso de validación cruzada implica subdividir la muestra en 10 grupos de igual tamaño, sacar uno de los grupos, estimar los modelos utilizando los datos de los 9 grupos restantes y medir su capacidad predictiva en el grupo extraído. El procedimiento continúa de manera iterativa hasta que cada uno de los 10 grupos sea evaluado fuera de la muestra.
Este procedimiento es relevante ya que permite evaluar la calidad de las estimaciones cuando los datos se encuentran fuera de la muestra. El promedio de los errores de estimación de los 10 grupos permite conocer cuál será el error de los modelos en aquellas zonas de la ciudad en donde no hay observaciones. Si, por el contrario, se evaluara la calidad de las estimaciones con los mismos datos utilizados en la construcción de los modelos, el error sería muy bajo, pero no se conocería cuál es la situación en aquellos lugares en donde no hay observaciones muestrales. Para medir el nivel de precisión de cada modelo se utilizó una métrica usualmente aplicada en la bibliografía; el error relativo promedio en valor absoluto (más conocido como mape por sus siglas en inglés: mean absolute percentage error)
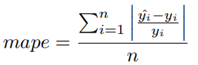
donde:

El proceso de validación cruzada indicó que el algoritmo que mejor predijo los valores del suelo fue Random Forest, con un mape de 31.8%. El algoritmo Support Vector Machine arrojó un mape de 37.16%, seguido del modelo Kernel K-nearest Neighbor con 37.63%. Sin embargo, si en lugar de considerar el error relativo promedio en valor absoluto se considera el error relativo mediano en valor absoluto, el nivel de error del algoritmo Random Forest baja considerablemente, llegando a 7.29%. Los niveles de error logrados son aceptables, más aún teniendo en cuenta de que se trata sólo de una prueba piloto y que hay mucha información adicional en Open Street Maps que no fue incluida en la estimación. La importancia relativa de las variables utilizadas se resume en la Fig. 2, en donde puede apreciarse un elevado nivel de dependencia espacial en torno a los datos de mayor valor del suelo y que la distancia a los bancos comerciales juega un rol preponderante. Además de la posición absoluta de los lotes en venta, se aprecia que las características del entorno son relevantes, ya que la variable que mide el nivel de consolidación del entorno mediante la clasificación de imágenes satelitales Sentinel 2 ocupa el cuarto puesto de importancia relativa en la determinación del modelo.

Fuente: elaboración propia en base a datos abiertos de Valores del Suelo en América Latina
Una vez identificado el modelo que arrojó un menor nivel de error, se procede a entrenar nuevamente este algoritmo (Random Forest) con la totalidad de los datos muestrales y a la estimación del valor del suelo en la base de datos de predicción (la grilla de puntos separados cada 100 metros). Si se rasteriza esta grilla de puntos se puede apreciar, en la Fig. 3, como queda determinada la estructura de valores del suelo estimados para la ciudad de Cochabamba, Bolivia, con valores que inician en 200 u$d/m2 en la periferia hasta 1.000 u$d/m2 en las zonas más caras de la ciudad.
Este breve ejercicio muestra el potencial de las técnicas de inteligencia artificial en los procesos de actualización masiva del suelo urbano y es un indicador de la importancia de las iniciativas de construcción colaborativa de datos abiertos, que ponen la información a disposición de la comunidad para lograr resultados que no hubieran sido posibles de otra forma. Si bien existen fuentes de datos georreferenciados abiertos, como Open Street Maps o la descarga libre de imágenes satelitales Landsat o Sentinel, la disponibilidad de información abierta relacionada a los mercados de suelo es escasa. Esta situación realza la utilidad del Mapa de Valores de América Latina para ciudades o regiones que requieran desarrollar mapas de valores preliminares o estimaciones sobre el impuesto predial.
.
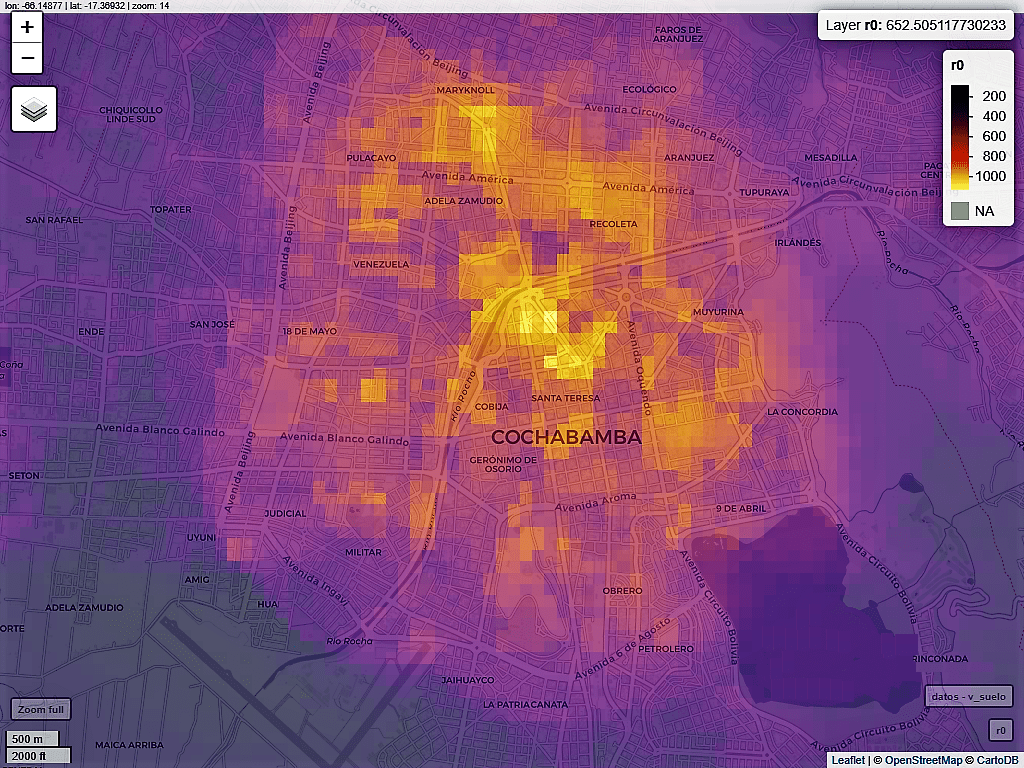
Fuente: elaboración propia en base a datos abiertos de Valores del Suelo en América Latina
