por Juan Pablo Carranza
Cuando relevamos datos del mercado inmobiliario en nuestro Observatorio, dependiendo de las metodologías de captura aplicadas, puede ser crítico llevar adelante un proceso de revisión de los mismos, a fin de lograr un conjunto de datos con la mayor calidad posible. Por ejemplo, si nuestro Observatorio tiene entre sus fuentes principales el scraping de páginas o la participación de voluntarios (crowdsourcing) es muy importante aplicar este tipo de post procesos.
Nuestro equipo aplicó técnicas geoestadísticas con el fin de mejorar la calidad de los conjuntos de datos disponibles para descarga. Te contamos cómo lo hicimos!
Alcance del análisis y técnicas aplicadas
El valor del suelo es un fenómeno social, que no obedece a reglas predefinidas. Se trata de un escenario sistémicamente caótico, que muchas veces refleja en el valor cuestiones subjetivas por parte de los propietarios que ponen en venta sus inmuebles. Si bien estas distorsiones suelen no convalidarse en una operación concreta, su existencia altera la «oferta inmobiliaria» observada en el proceso de relevamiento de información. Esto hace necesario, entonces, tomar ciertos recaudos a la hora de validar la carga de datos o de definir qué datos finalmente se usarán en la modelización o construcción de los mapas de valores de suelo.
El proceso de análisis aplicado a los datos 2016, 2017 y 2018 del Mapa de Valores de Suelo en América Latina, consistió en la identificación de observaciones atípicas en su entorno (Fig. 1) mediante el cálculo del índice de Moran local, que define la auto-correlación espacial entre las observaciones. El índice de Moran local parte del supuesto denominado «ley de Tobler», o principio de auto-correlación espacial, donde los objetos más próximos en el espacio tienden a exhibir un grado de similitud mayor que los objetos más distantes.
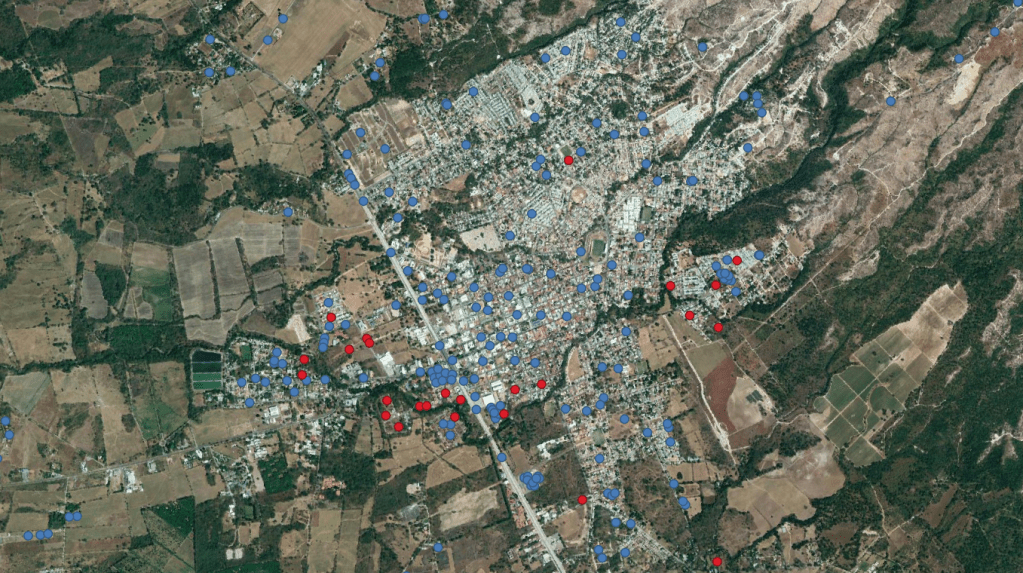
Para su cálculo se debe, en primer lugar, definir un vecindario; es decir, un ambiente en donde las observaciones deben presentar características comunes que determinen un comportamiento similar en la variable de estudio (en este caso, el valor del suelo). El vecindario fue fijado como el espacio comprendido en un radio de 500 m de cada observación. Esta distancia se definió en base al rango de un semivariograma que captura la estructura de la dependencia espacial de los valores del suelo, a partir de las bases de datos utilizadas.
Con estos insumos se procedió, entonces, al cálculo del índice de Moran local, que asume valores comprendidos entre -1 y 1, siendo los más próximos a -1 aquellos que muestran valores de suelo más diferentes a su entorno y los más próximo a 1, un valor de suelo similar al de su entorno. Las observaciones que muestran un índice cercano a cero no presentan dependencia espacial con los datos de su entorno.
Es importante notar que esta revisión hace referencia a la calidad del dato tal cual fue relevado del mercado, y no a la calidad del trabajo de las instituciones o voluntarios que participan de la iniciativa.
Resultados obtenidos
Con los primeros resultados se procedió a quitar de la base aquellas observaciones que muestran un índice de Moran local negativo y estadísticamente significativo al 5% (es decir, un nivel de confianza del 95% para rechazar la hipótesis nula de independencia espacial).
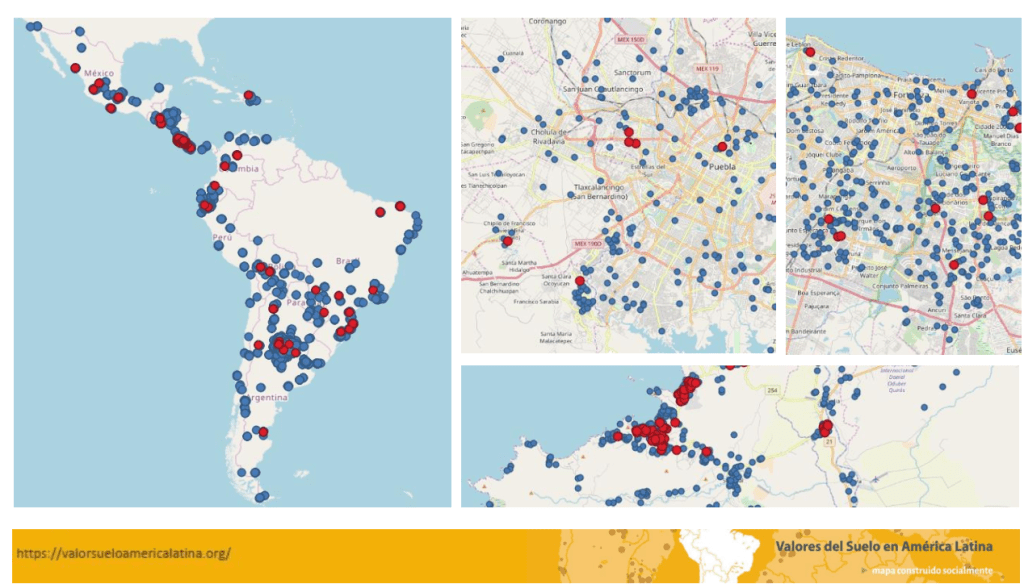
Esta definición metodológica implicó el retiro de 454 observaciones (1,5%) de la base de datos de los 3 años señalados, por ser consideradas atípicas en su entorno. Así, las bases de datos depuradas quedaron conformadas por: 3.192 muestras correspondientes a la edición 2016 (se eliminan 49 datos), 8.509 de la edición 2017 (se eliminan 270 observaciones) y 18.379 datos en la edición 2018 (se eliminan 135 casos). Para las ediciones 2016, 2017 y 2018 el mapa quedó formado por un total de 30.080 datos distribuidos en casi todos los países y principales ciudades de la región.
Para acceder a las nuevas base de datos, ir la sección «Datos».

Muy interesante el análisis estimado Sergio.
Si en una primera parte se identifica la correlación espacial mediante el Índice de Moran (Medida de asociación basada en una matriz de ponderaciones espaciales), tal vez en una siguiente etapa aplicar un Modelo Autorregresivo Espacial, a manera de identificar el grado de influencia del valor de las muestras vecinas en la determinación del precio del inmueble, ahora entrando en otra etapa tal vez correr una Regresión Geográficamente Ponderada (GWR) para ver el valor de las muestras de acuerdo a su localización.
Además sería interesante analizar desde el punto de vista de la paradoja de Simpson.
Gracias por las publicaciones, se aprende bastante de este tipo de trabajos.
Saludos.
Me gustaMe gusta
Estimado Alfredo,
Muchas gracias por tus comentarios. En esta experiencia, lo valioso está, además de la participación voluntaria de la iniciativa, en investigar, explorar e intercambiar experiencias en un aprendizaje continúo. Agradecemos tus ponderaciones y perspectiva técnica, Juan Pablo Carranza, nuestro compañero economista agradecerá el aporte.
Saludos cordiales desde Córdoba, Argentina!
Sergio
Me gustaMe gusta